I mean - have you followed AI news? This whole thing kicked off maybe three years ago, and now local models can render video and do half-decent reasoning.
None of it’s perfect, but a lot of it’s fuckin’ spooky, and any form of “well it can’t do [blank]” has a half-life.
Seen a few YouTube channels now that just print out AI generated content. Usually audio only with a generated picture on screen. Vast amounts could be made so cheaply like that, Google is going to have fun storing all that when each only gets like 25 views. I think at some point they are going to have to delete stuff.
I kid you not, I took ML back in 2014 as a extra semester in my undergrad. The complaints then were the same as complaints now: too much power requirement, too many false positives. The latter of the two has evolved into hallucinations.
If normal people going “I made this!” is not convincing enough that it is easily identified then who is this going to replace? you still need the right expert right? all it creates is more work for experts to come and fix broken AI output.
The complaints then were the same as complaints now
Despite results improving at an insane rate, very recently. And you think this is proof of a problem with… the results? Not the complaints?
People went “I made this!” with fucking Terragen. A program that renders wild alien landscapes which became generic after about the fifth one you saw. The problem there is not expertise. It’s immense quantity for zero effort. None of that proves CGI in general is worthless non-art. It’s just shifting what the computer will do for free.
At some point, we will take it for granted that text-to-speech can do an admirable job reading out whatever. It’ll be a button you push when you’re busy sometimes. The dipshits mass-uploading that for popular articles, over stock footage, will be as relevant as people posting seven thousand alien sunsets.
the results do keep improving of course. But it’s not some silver bullet. Yes, your enthusiasm is warranted… but you peddle it like the 2nd coming of christ which I don’t like encouraging.
That turns out to be good enough, for a bunch of applications. Even the parts that are just a chatbot fooling people are useful. And massively better than the era you’re comparing this to.
We have to deal with this honestly. Neural networks have officially caught on, and anything with examples can be approximated. Anything. The hard part is reminding people what “approximated” means. Being wrong sometimes is normal. Humans are wrong about all kinds of stuff. But for some reason, people think computers bring unflinching perfection - and approach life-or-death scenarios with this sloppy magic.
Personally I’m excited for position tracking with accelerometers. Naively integrating into velocity and location immediately sends you to outer space. Clever filtering almost sorta kinda works. But it’s a complex noisy problem, with a minimal output, where approximate answers get partial credit. So long as it’s tuned for walking around versus riding a missile, it should Just Work.
Similarly restrained use-cases will do minor witchcraft on a pittance of electricity. It’s not like matrix math is hard, for computers. LLMs just try to do as much of it as possible.
If you follow AI news you should know that it’s basically out of training data, that extra training is inversely exponential and so extra training data would only have limited impact anyway, that companies are starting to train AI on AI generated data -both intentionally and unintentionally, and that hallucinations and unreliability are baked-in to the technology.
You also shouldn’t take improvements at face value. The latest chatGPT is better than the previous version, for sure. But its achievements are exaggerated (for example, it already knew the answers ahead of time for the specific maths questions that it was denoted answering, and isn’t better than before or other LLMs at solving maths problems that it doesn’t have the answers already hardcoded), and the way it operates is to have a second LLM check its outputs. Which means it takes,IIRC, 4-5 times the energy (and therefore cost) for each answer, for a marginal improvement of functionality.
The idea that “they’ve come on in leaps and bounds over the Last 3 years therefore they will continue to improve at that rate isn’t really supported by the evidence.
We don’t need leaps and bounds, from here. We’re already in science fiction territory. Incremental improvement has silenced a wide variety of naysaying.
And this is with LLMs - which are stupid. We didn’t design them with logic units or factoid databases. Anything they get right is an emergent property from guessing plausible words, and they get a shocking amount of things right. Smaller models and faster training will encourage experimentation for better fundamental goals. Like a model that can only say yes, no, or mu. A decade ago that would have been an impossible sell - but now we know data alone can produce a network that’ll fake its way through explaining why the answer is yes or no. If we’re only interested in the accuracy of that answer, then we’re wasting effort on the quality of the faking.
Even with this level of intelligence, where people still bicker about whether it is any level of intelligence, dumb tricks keep working. Like telling the model to think out loud. Or having it check its work. These are solutions an author would propose as comedy. And yet: it helps. It narrows the gap between “but right now it sucks at [blank]” and having to find a new [blank]. If that never lets it do math properly, well, buy a calculator.
I’m not saying they don’t have applications. But the idea of them being a one size fits all solution to everything is something being sold to VC investors and shareholders.
As you say - the issue is accuracy. And, as you also say - that’s not what these things do, and instead they make predictions about what comes next and present that confidently. Hallucinations aren’t errors, they’re what they were built to do.
If you want something which can set an alarm for you or find search results then something that responds to set inputs correctly 100% of the time is better than something more natural-seeming which is right 99%of the time.
Maybe along the line there will be a new approach, but what is currently branded as AI is never going to be what it’s being sold as.
If you want something more complex than an alarm clock, this does kinda work for anything. Emphasis on “kinda.”
Neural networks are universal approximators. People get hung-up on the approximation part, like that cancels out the potential in… universal. You can make a model that does any damn thing. Only recently has that seriously meant you and can - backpropagation works, and it works on video-game hardware.
what is currently branded as AI
“AI is whatever hasn’t been done yet” has been the punchline for decades. For any advancement in the field, people only notice once you tell them it’s related to AI, and then they just call it “AI,” and later complain that it’s not like on Star Trek.
And yet it moves. Each advancement makes new things possible, and old things better. Being right most of the time is good, actually. 100% would be better than 99%, but the 100% version does not exist, so 99% is better than never.
Telling the grifters where to shove it should not condemn the cool shit they’re lying about.
My main point WRT “kinda” is that there are a tonne of applications that 99% isn’t good enough for.
For example, one use that all the big players in the phone world seem to be pushing ATM is That of sorting your emails for you. If you rely on that and it classifies an important email as unimportant so you miss it, then that’s actually a useless feature. Either you have to check all your emails manually yourself, in which case it’s quicker to just do that in the first place and the AI offers no value, or you rely on it and end up missing something that it es important you didn’t miss.
And it doesn’t matter if it gets it wrong one time in a hundred, that one time is enough to completely negate all potential positives of the feature.
As you say, 100% isn’t really possible.
I think where it’s useful is for things like analysing medical data and helping coders who know what they’re doing with their work. In terms of search it’s also good at “what’s the name of that thing that’s kinda like this?”-type queries. Kind of the opposite of traditional search engines where you’re trying to find out information about a specific thing, where i think non-Google engines are still better.
Your example of catastrophic failure is… e-mail? Spam filters are wrong all the time, and they’re still fantastic. Glancing in the folder for rare exceptions is cognitively easier than categorizing every single thing one-by-one.
If there’s one false negative, you don’t go “Holy shit, it’s the actual prince of Nigeria!”
But sure, let’s apply flawed models somewhere safe, like analyzing medical data. What?
And it doesn’t matter if it gets it wrong one time in a hundred, that one time is enough to completely negate all potential positives of the feature.
Obviously fucking not.
Even in car safety, a literal life-and-death context, a camera that beeps when you’re about to screw up can catch plenty of times where you might guess wrong. Yeah - if you straight-up do not look, and blindly trust the beepy camera, bad things will happen. That’s why you have the camera and look.
If a single fuckup renders the whole thing worthless, I have terrible news about human programmers.
Okay, so you can’t conceive of the idea of an email that it’s important that you don’t miss.
Let’s go with what Apple sold Apple Intelligence on, shall we? You say to Siri “what time do I need to pick my mother up from the airport?” and Siri coombs through your messages for the flight time, checks the time of arrival from the airline’s website, accesses maps to get journey time accounting for local traffic, and tells you when you need to leave.
With LLMs, absolutely none of those steps can be trusted. You have to check each one yourself. Because if they’re wrong, then the output is wrong. And it’s important that the output is right. And if you have to check the input of every step, then what do you save by having Siri do it in the first place? It’s actually taking you more time than it would have to do everything yourself.
AI assistants are being sold as saving you time and taking meaningless busywork away from you. In some applications, like writing easy, boring code, or crunching more data than a human could in a very short time frame, they are. But for the applications they’re being sold on for phones? Not without being reliable. Which they can’t be, because of their architecture.

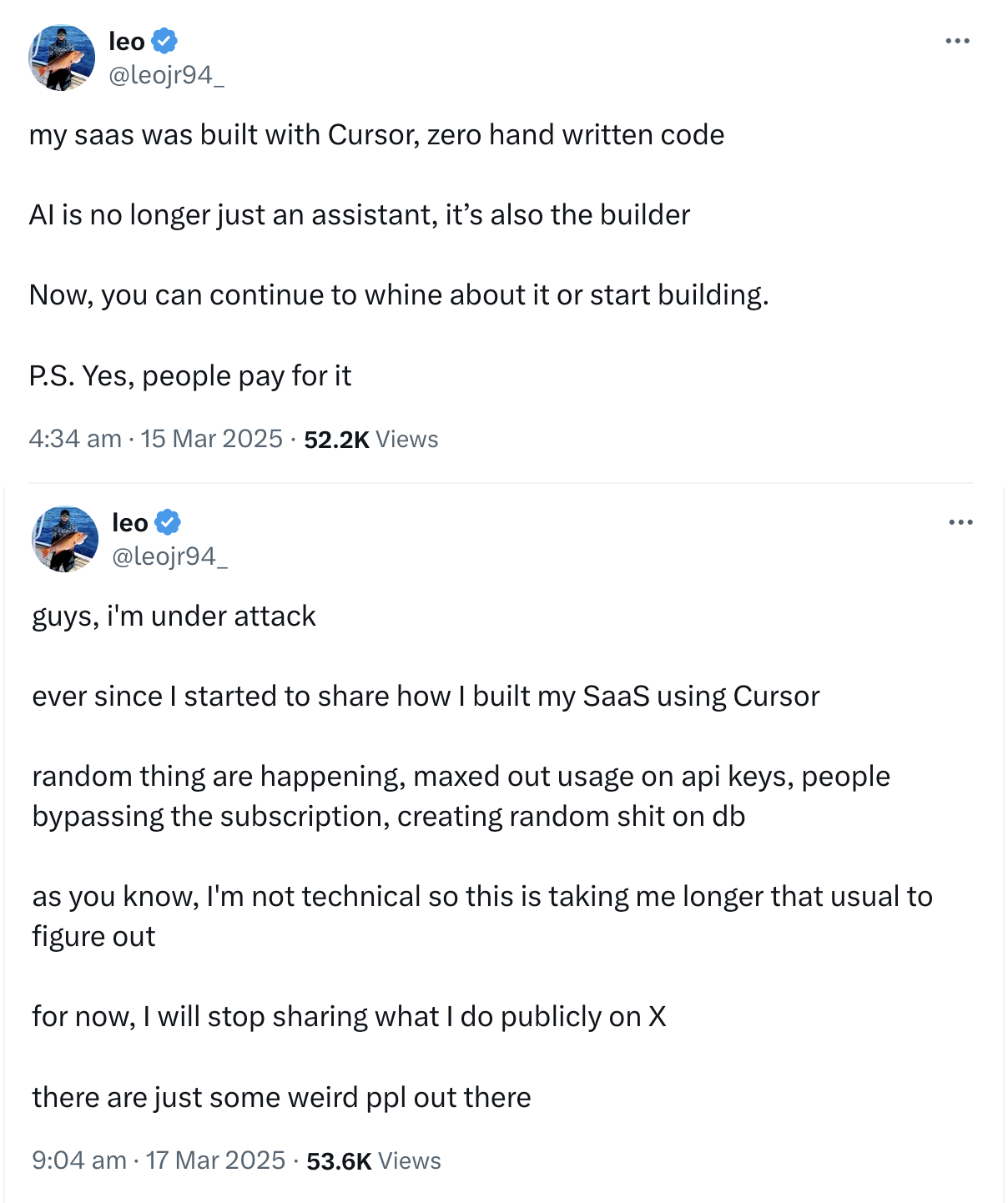{kind=link}
“more breakthroughs” spoken like we get these once everyday like milk delivery.
I mean - have you followed AI news? This whole thing kicked off maybe three years ago, and now local models can render video and do half-decent reasoning.
None of it’s perfect, but a lot of it’s fuckin’ spooky, and any form of “well it can’t do [blank]” has a half-life.
Seen a few YouTube channels now that just print out AI generated content. Usually audio only with a generated picture on screen. Vast amounts could be made so cheaply like that, Google is going to have fun storing all that when each only gets like 25 views. I think at some point they are going to have to delete stuff.
Dipshits going “I made this!” is not indicative of what this makes possible.
I kid you not, I took ML back in 2014 as a extra semester in my undergrad. The complaints then were the same as complaints now: too much power requirement, too many false positives. The latter of the two has evolved into hallucinations.
If normal people going “I made this!” is not convincing enough that it is easily identified then who is this going to replace? you still need the right expert right? all it creates is more work for experts to come and fix broken AI output.
Despite results improving at an insane rate, very recently. And you think this is proof of a problem with… the results? Not the complaints?
People went “I made this!” with fucking Terragen. A program that renders wild alien landscapes which became generic after about the fifth one you saw. The problem there is not expertise. It’s immense quantity for zero effort. None of that proves CGI in general is worthless non-art. It’s just shifting what the computer will do for free.
At some point, we will take it for granted that text-to-speech can do an admirable job reading out whatever. It’ll be a button you push when you’re busy sometimes. The dipshits mass-uploading that for popular articles, over stock footage, will be as relevant as people posting seven thousand alien sunsets.
the results do keep improving of course. But it’s not some silver bullet. Yes, your enthusiasm is warranted… but you peddle it like the 2nd coming of christ which I don’t like encouraging.
I’ve done no such thing.
I called it half-decent, spooky, and admirable.
That turns out to be good enough, for a bunch of applications. Even the parts that are just a chatbot fooling people are useful. And massively better than the era you’re comparing this to.
We have to deal with this honestly. Neural networks have officially caught on, and anything with examples can be approximated. Anything. The hard part is reminding people what “approximated” means. Being wrong sometimes is normal. Humans are wrong about all kinds of stuff. But for some reason, people think computers bring unflinching perfection - and approach life-or-death scenarios with this sloppy magic.
Personally I’m excited for position tracking with accelerometers. Naively integrating into velocity and location immediately sends you to outer space. Clever filtering almost sorta kinda works. But it’s a complex noisy problem, with a minimal output, where approximate answers get partial credit. So long as it’s tuned for walking around versus riding a missile, it should Just Work.
Similarly restrained use-cases will do minor witchcraft on a pittance of electricity. It’s not like matrix math is hard, for computers. LLMs just try to do as much of it as possible.
If you follow AI news you should know that it’s basically out of training data, that extra training is inversely exponential and so extra training data would only have limited impact anyway, that companies are starting to train AI on AI generated data -both intentionally and unintentionally, and that hallucinations and unreliability are baked-in to the technology.
You also shouldn’t take improvements at face value. The latest chatGPT is better than the previous version, for sure. But its achievements are exaggerated (for example, it already knew the answers ahead of time for the specific maths questions that it was denoted answering, and isn’t better than before or other LLMs at solving maths problems that it doesn’t have the answers already hardcoded), and the way it operates is to have a second LLM check its outputs. Which means it takes,IIRC, 4-5 times the energy (and therefore cost) for each answer, for a marginal improvement of functionality.
The idea that “they’ve come on in leaps and bounds over the Last 3 years therefore they will continue to improve at that rate isn’t really supported by the evidence.
We don’t need leaps and bounds, from here. We’re already in science fiction territory. Incremental improvement has silenced a wide variety of naysaying.
And this is with LLMs - which are stupid. We didn’t design them with logic units or factoid databases. Anything they get right is an emergent property from guessing plausible words, and they get a shocking amount of things right. Smaller models and faster training will encourage experimentation for better fundamental goals. Like a model that can only say yes, no, or mu. A decade ago that would have been an impossible sell - but now we know data alone can produce a network that’ll fake its way through explaining why the answer is yes or no. If we’re only interested in the accuracy of that answer, then we’re wasting effort on the quality of the faking.
Even with this level of intelligence, where people still bicker about whether it is any level of intelligence, dumb tricks keep working. Like telling the model to think out loud. Or having it check its work. These are solutions an author would propose as comedy. And yet: it helps. It narrows the gap between “but right now it sucks at [blank]” and having to find a new [blank]. If that never lets it do math properly, well, buy a calculator.
I’m not saying they don’t have applications. But the idea of them being a one size fits all solution to everything is something being sold to VC investors and shareholders.
As you say - the issue is accuracy. And, as you also say - that’s not what these things do, and instead they make predictions about what comes next and present that confidently. Hallucinations aren’t errors, they’re what they were built to do.
If you want something which can set an alarm for you or find search results then something that responds to set inputs correctly 100% of the time is better than something more natural-seeming which is right 99%of the time.
Maybe along the line there will be a new approach, but what is currently branded as AI is never going to be what it’s being sold as.
If you want something more complex than an alarm clock, this does kinda work for anything. Emphasis on “kinda.”
Neural networks are universal approximators. People get hung-up on the approximation part, like that cancels out the potential in… universal. You can make a model that does any damn thing. Only recently has that seriously meant you and can - backpropagation works, and it works on video-game hardware.
“AI is whatever hasn’t been done yet” has been the punchline for decades. For any advancement in the field, people only notice once you tell them it’s related to AI, and then they just call it “AI,” and later complain that it’s not like on Star Trek.
And yet it moves. Each advancement makes new things possible, and old things better. Being right most of the time is good, actually. 100% would be better than 99%, but the 100% version does not exist, so 99% is better than never.
Telling the grifters where to shove it should not condemn the cool shit they’re lying about.
I’m not sure we’re disagreeing very much, really.
My main point WRT “kinda” is that there are a tonne of applications that 99% isn’t good enough for.
For example, one use that all the big players in the phone world seem to be pushing ATM is That of sorting your emails for you. If you rely on that and it classifies an important email as unimportant so you miss it, then that’s actually a useless feature. Either you have to check all your emails manually yourself, in which case it’s quicker to just do that in the first place and the AI offers no value, or you rely on it and end up missing something that it es important you didn’t miss.
And it doesn’t matter if it gets it wrong one time in a hundred, that one time is enough to completely negate all potential positives of the feature.
As you say, 100% isn’t really possible.
I think where it’s useful is for things like analysing medical data and helping coders who know what they’re doing with their work. In terms of search it’s also good at “what’s the name of that thing that’s kinda like this?”-type queries. Kind of the opposite of traditional search engines where you’re trying to find out information about a specific thing, where i think non-Google engines are still better.
Your example of catastrophic failure is… e-mail? Spam filters are wrong all the time, and they’re still fantastic. Glancing in the folder for rare exceptions is cognitively easier than categorizing every single thing one-by-one.
If there’s one false negative, you don’t go “Holy shit, it’s the actual prince of Nigeria!”
But sure, let’s apply flawed models somewhere safe, like analyzing medical data. What?
Obviously fucking not.
Even in car safety, a literal life-and-death context, a camera that beeps when you’re about to screw up can catch plenty of times where you might guess wrong. Yeah - if you straight-up do not look, and blindly trust the beepy camera, bad things will happen. That’s why you have the camera and look.
If a single fuckup renders the whole thing worthless, I have terrible news about human programmers.
Okay, so you can’t conceive of the idea of an email that it’s important that you don’t miss.
Let’s go with what Apple sold Apple Intelligence on, shall we? You say to Siri “what time do I need to pick my mother up from the airport?” and Siri coombs through your messages for the flight time, checks the time of arrival from the airline’s website, accesses maps to get journey time accounting for local traffic, and tells you when you need to leave.
With LLMs, absolutely none of those steps can be trusted. You have to check each one yourself. Because if they’re wrong, then the output is wrong. And it’s important that the output is right. And if you have to check the input of every step, then what do you save by having Siri do it in the first place? It’s actually taking you more time than it would have to do everything yourself.
AI assistants are being sold as saving you time and taking meaningless busywork away from you. In some applications, like writing easy, boring code, or crunching more data than a human could in a very short time frame, they are. But for the applications they’re being sold on for phones? Not without being reliable. Which they can’t be, because of their architecture.
That’s your interpretation.
that’s reality. Unless you’re too deluded to think it’s magic.
No i meant to say you’re interpretation of what I said.