No, that should be a parameterized script (/unit test/function/what ever, just picking up your example). If you have a repeating pattern with slight changes “AI” can generate more of that (to some degree), but it cannot fix the code duplication. Every line of code written is a line of code that has to be maintained.
It’s actually one of the things copilot gets advertised for: see how great copilot can generate more of these repetitive unit tests? Yah, great, write more garbage faster. People need to know about test theories (parameterized tests) and think about what they’re doing.
So you copy your script 10 times with minor changes (or let copilot & co do it) and notice there’s some flaw in the script you started with; now you have to change 11 scripts - great.
Well it’s intentional duplication because they get deployed to separate instances, different resources types, different regions, using different resources, different logic, and different source triggers/types, and different destinations.
Fair enough. There might be some niche use cases where the results might be acceptable. But with everything I’ve seen I don’t trust “AI” with anything.
I’m with you there, I guess I don’t fully disagree. I have coworkers who use AI for like 80% of their work and I don’t get it. Half the time I feel like they spend more time figuring out what it did and fixing it versus they could’ve done it themselves from scratch faster (…or maybe they couldn’t?)
I’d say my use is closer to 10% for raw code and maybe 25% for intelligent tab completions. The black box of outputs just kinda weirds me out, even if I can see a diff.

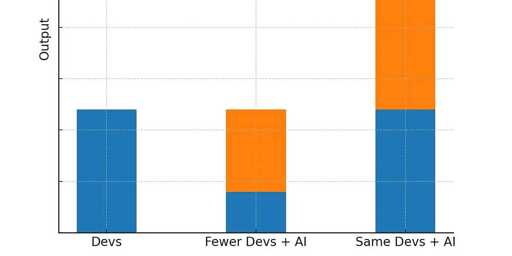
No, that should be a parameterized script (/unit test/function/what ever, just picking up your example). If you have a repeating pattern with slight changes “AI” can generate more of that (to some degree), but it cannot fix the code duplication. Every line of code written is a line of code that has to be maintained.
It’s actually one of the things copilot gets advertised for: see how great copilot can generate more of these repetitive unit tests? Yah, great, write more garbage faster. People need to know about test theories (parameterized tests) and think about what they’re doing.
So you copy your script 10 times with minor changes (or let copilot & co do it) and notice there’s some flaw in the script you started with; now you have to change 11 scripts - great.
Well it’s intentional duplication because they get deployed to separate instances, different resources types, different regions, using different resources, different logic, and different source triggers/types, and different destinations.
So I disagree. Still, fuck Copilot.
Fair enough. There might be some niche use cases where the results might be acceptable. But with everything I’ve seen I don’t trust “AI” with anything.
I’m with you there, I guess I don’t fully disagree. I have coworkers who use AI for like 80% of their work and I don’t get it. Half the time I feel like they spend more time figuring out what it did and fixing it versus they could’ve done it themselves from scratch faster (…or maybe they couldn’t?)
I’d say my use is closer to 10% for raw code and maybe 25% for intelligent tab completions. The black box of outputs just kinda weirds me out, even if I can see a diff.